
In an attempt to broaden my approach to this blogging lark, I thought I’d turn my hand to some linguistic analysis. This presents a problem in the form of my being a qualified mathematician and therefore acutely aware of how easy it is to skew any set of data based on the interpretation it’s given, and thus how pointless it becomes to really bother. Nevertheless, I shall sally forth into the Sherlock Holmes canon with a quick sweep over some of the main points, and I can always come back to it later if I feel it warrants further investigation.
All numbers come from a combination of internet-based textual analysis tool Voyant and the texts of Conan Doyle’s Holmes canon as provided at The Complete Sherlock Holmes website. Some numbers have been slightly simplified for reasons that are too dull to go into here, but feel free to pull me up on my maths in the comments if any of it seems ridiculously suspicious.
The entire canon is some 670,000 words composed of around 25,000 unique terms – or, to put it another way, you can write a list of every word ever used by Conan Doyle in writing the canon and it would only be 25,000 items long. All told this is a fairly prodigious vocabulary: famed Elizabethan wordsmith Wm. Shakespeare (putting all authorship contentions aside for the time being) is credited with around 884,000 words – practically a third as much again as Conan Doyle – yet only has around 28,000 distinct words, or around one eighth more. Now, of course, here we stumble upon our first statistical problem: there were fewer words in the English language back then (there’s quite a broad disagreement as to how many…), but then equally Shakespeare invented a great many words (‘eyeball’ for one) and so wouldn’t be restricted in quite the same way as his contemporaries. To put Conan Doyle’s written expression into another context, there are around 250,000 recognised (in use and defunct) words in the English language today; so around 100 years ago he was already using 10% of the modern version of the language. Consider the number of words that have been added in that time – robot, computer, internet, unleaded, twerking – and the rate at which English has expanded and that’s a pretty impressive sweep.
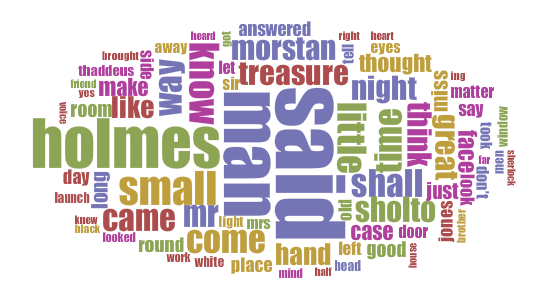
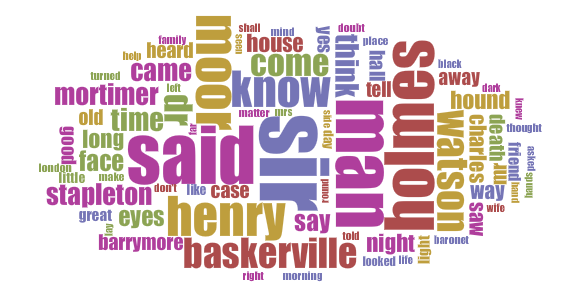
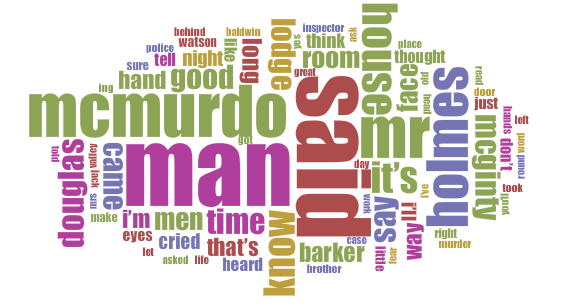
Nevertheless, the stories were and have remained hugely popular and so must be accessible. This means that Conan Doyle’s prose must have been easy to read and must have contained ideas that are easy to understand even over a century later. Here are cirrus displays produced by Voyant of the most popular words in each of the Holmes novels or collections, filtered to remove the most common conjunctions (and, it, of, the, to, etc.), around fifty common words (if, is, with, etc.) and all numbers. I have also included (without these exclusions) the approximate total words for each book and the percentage of unique words in each book; to put this in context, a 100-word story with 10% of the words being unique would effectively be composed of the same ten words repeated ten times each:
A Study in Scarlet (1887)
44,000 words; 14% unique
 The Sign of Four (1890)
The Sign of Four (1890)
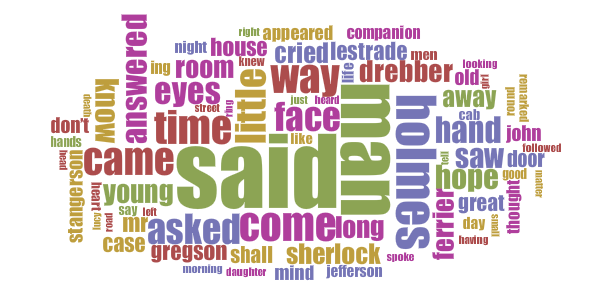
44,000 words; 14% unique
 The Adventures of Sherlock Holmes (1892)
The Adventures of Sherlock Holmes (1892)
106,000 words; 9% unique

The Memoirs of Sherlock Holmes (1893)
88,000 words; 9% unique

The Hound of the Baskervilles (1901-1902)
60,000 words; 10% unique
 The Return of Sherlock Holmes (1905)
The Return of Sherlock Holmes (1905)
114,000 words; 8% unique

The Valley of Fear (1914-1915)
58,000 words; 11% unique
His Last Bow (1917)
69,000 words; 11% unique
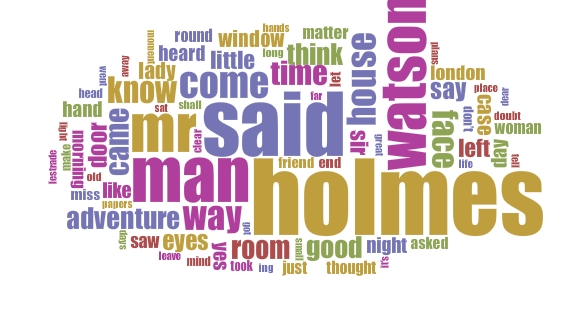
The Case-Book of Sherlock Holmes (1927)
84,000 words; 10% unique


Really enjoyed reading this post and it must have taken a lot of time and effort to do the cirrus displays (being an English Literature degree person I was going to call them the nice wordy pictures but I figured a mathematically minded person might baulk at that). Something that stood out for me in your analysis was the fact that the language used is very concrete as opposed to abstract and there is not a great deal of emotions expressed apart from the odd ‘cried’. This might of course be a way of making it an easier read, but I also wondered whether this is another way detective literature at this time, was trying to steer away from sensation fiction a bit and emphasis instead the idea of physical clues, reasoning, logic and data. I suppose also the precise nature of the language links into the more scientific approach Holmes tries to use in his investigation (which I believe Ian Ousby in his book Bloodhounds of Heaven picks up on). The vogue for scientific detectives at the time would suggest Doyle wasn’t the only one doing this. On a final note originally A Study in Scarlet was going to be called A Tangled Skein – which could be classed as weaker but definitely more abstract title, but the fact it wasn’t used and a much more simpler, concrete title was used instead I think reflects the sensing and concrete language used in the stories. Sorry for the blithering on so much, hadn’t quite realised I had written so much!
LikeLiked by 1 person
That’s not blithering at all, Kate, you make a series of excellent points. I have very little experience with late-Victorian literature full stop, but am particularly ignorant of the context of sensationalist writing from that time and you’re quite correct about the lack of fully emotive language in evidence (these not being the types of words I excluded). Reasoning and logic certainly seem to be the touchstones of the Holmes series, and ‘think’ is a popular word in the canon – whereas ‘feel’ or ‘imagine’ and their equivalent forms come decidely further down. It would be intersting to see how someone like R. Austin Freeman compares, or to take the text of something sensationalist from the same era (any suggestions?) and see what it turns up under similar conditions.
Thank-you, this has really got me thinking now!
LikeLiked by 1 person
Although sensation fiction can be a little annoying with its weak kneed ninnys for heroines, as a subgenre I have become increasing conscious of how important it was in contributing to detective fiction, especially with writers like Wilkie Collins and Charles Dickens blurring the boundaries considerably such as The Woman in White and The Bleak House. Think a key commonality between the genres is that they both suggest that respectability can be skin deep and also that murder and other crimes really do begin at home. Sensation fiction though did I think manage to vamp up the figure of the villain and make it more 3 dimensional than melodrama tended to do at the time. The primary difference though is that crime fiction tends to focus on how the crime or mystery is uncovered, whereas in sensation fiction you tend to know the mystery early on but are reading to find out what the bad character does next and how they will get their comeuppance. Another difference of course is the use of detectives as in sensation fiction such as Lady Audley’s Secret it is a relative which does the detecting whereas in crime fiction detectives can be relatives, policeman or amateurs etc. I think there would be a very stark contrast between an example of sensation fiction and a story from Freeman. Don’t know of any sensation fiction short stories off the top of my head but Lady Audley’s Secret would be a good example of sensation fiction tropes and language and is also considerably shorter than The Woman in White, which I swear has nearly 200 pages of padding at the end where the previous 400 odd pages are recounted (despite that though it is a good read in other respects). If you’re interested in finding out a bit more about Victorian crime fiction (melodrama, real life crimes, sensation fiction and detective fiction and how it developed and was intertwined) Judith Flander’s The Invention of Murder is a really good, not too long and informative read and a bit like Martin Edwards’ book it isn’t a list of facts but more of a narrative.
LikeLiked by 1 person
An astonishgly thorough response…I’m a little in awe of how quickly you can cite ll this stuff. I know I want to follow this up in some way, it’s too interesting an idea not to do something with it, but let me go away and digest this and work out how…!
LikeLiked by 1 person
haha yeah I do have a tendency for writing way too much. I did an independent project in my 2nd year of uni on melodrama and Sherlock Holmes so that was when I came across most of what I know on sensation fiction etc. and read the Flanders book.
LikeLiked by 1 person
Dude, very cool! I smell a post for you right there…
LikeLike
well I actually used it in an article I submitted for the next issue of CADs, so that’ll hopefully be appearing next year some time.
LikeLiked by 1 person
The sensation novelists are worth checking out. Sheridan le Fanu’s WYLDER’S HAND is particularly good and would be a good starting point. He was better known for his superb gothic fiction but he wrote sensation novels as well, and very good ones.
Wilkie Collins is excellent. Mary Braddon’s LADY AUDLEY’S SECRET is also not bad.
I’d start with WYLDER’S HAND – there’s less padding.
LikeLiked by 1 person
Beautiful, many thanks, I shall put it in my list – not a genre I know at all, so a recommednation is greatly appreciated.
LikeLike
Not a mathematician, but as someone who has spent quite some time with (socio-)linguistics, I found this a highly entertaining post. I remember that quite some years ago, researchers also took a similar look at Christie’s work, which (IIRC) showed she used a (relatively) small vocabulary, with sentences of a certain length and other properties that made her writing very accessible to the reader.
LikeLiked by 1 person
Mathematicians, socio-linguists, we take all kinds here! A comparison of Christie’s texts would be fascinating – as would looking at someone like Sayers or Chesterton who doubtless must have used a greater range of terms. I shall be coming back to this at some point, I imagine, as it’s lovely to see it’s capturing people’s interest – thanks so much for taking the time to comment.
LikeLike
Sorry to jump in, but I remembered that a few weeks ago Mark Green did a post for the Tuesday Night Bloggers on the readability of the various detection club writers using the Gunning Fog index: http://bodiesfromthelibrary.com/2015/10/27/the-detection-clubs-fogginess/
I thought you hadn’t come across it already it might be of some interest.
LikeLiked by 1 person
That was awesome, many thanks. I have a feeling it was flagged up on Twitter, but I managed to miss it in the rush of everything else.
LikeLike
Pingback: #54: The Kings of Crime – IV: Erle Stanley Gardner, the King of Spades | The Invisible Event
Pingback: #84: The Tuesday Night Bloggers – The Sherlockian Impossibilities of John Dickson Carr – II: ‘The Adventure of the Sealed Room’ (1953) | The Invisible Event